
Disclaimer:Hey Guys, this post contains affiliate link to help our reader to buy best product\service for them. It helps us because we receive compensation for our time and expenses.
Scenario:-
One of our UAT database environment which was setup with Active-Active fail-over cluster approach ran into inaccessible for the application and DBA was asked to take a look inside the database server.
On checking from the database side, I found that the SQL resource group was failed in the status in cluster management dashboard and obvious SQL service and Agent were offline.
I further checked the cluster event and found the below error which was quite self descriptive.

Error Message:
Clustered role 'Cluster Group' has exceeded its failover threshold. It has exhausted the configured number of failover attempts within the failover period of time allotted to it and will be left in a failed state. No additional attempts will be made to bring the role online or fail it over to another node in the cluster. Please check the events associated with the failure. After the issues causing the failure are resolved the role can be brought online manually or the cluster may attempt to bring it online again after the restart delay period. The Cluster service failed to bring clustered role 'Cluster Group' completely online or offline. One or more resources may be in a failed state. This may impact the availability of the clustered role.

Possible Root Cause:
In lab sometimes, for testing purposes , we intentionally do cluster fail-over several times within a short period of time and there is a setting in Cluster management which measures the fail-over count.
- If that count hits a particular threshold, it flags the Resource Group as ‘Failed’ state
- And creates an entry in the the Cluster Events, that Cluster Resource Group failed after reaching the threshold (see the error message above)
Resolution:
>Go to Fail-over Cluster Manager –> Roles –> right click on the Resource Group and to go Properties:
- Change the Maximum failures in a specified period to a larger number to account for the repeated fail-overs in recent hour.
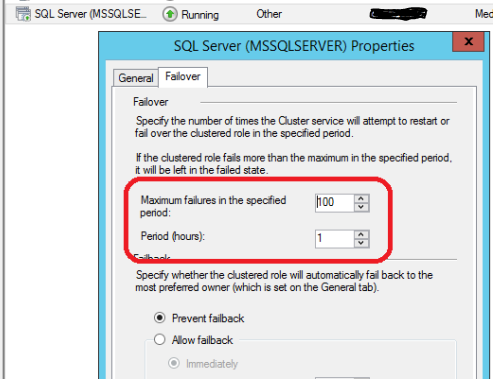
>Try to bring the resource online.
>In our case even after increasing the threshold, resource was unable to come online and it was capturing same error messages in the cluster event log.
>On further investigation, found that there was some issue with the password for SQL service running account, its password was expired.
>Post applying updated password from Vault, resource was brought online.
>So, there were 2 possible causes, one was threshold and second was password issue.
Hope this helps!

The fragrance of flowers spreads only in the direction of the wind. But the goodness of a person spreads in all directions.
Chanakya

You must be logged in to post a comment.