
Disclaimer:Hey Guys, this post contains affiliate link to help our reader to buy best product\service for them. It helps us because we receive compensation for our time and expenses.

Lets Begin:-
In this series, we will walk through life cycle of SQL server. Its SQL server 2012 architecture, we have many more new and advanced components introduced and will get introduced in latest version of SQL server. The intention of this blog is to at-least give a basis idea of architecture and SQL query execution.

A Basic SELECT Statement Life Cycle Summary
Figure shows the whole life cycle of a SELECT query, described here:
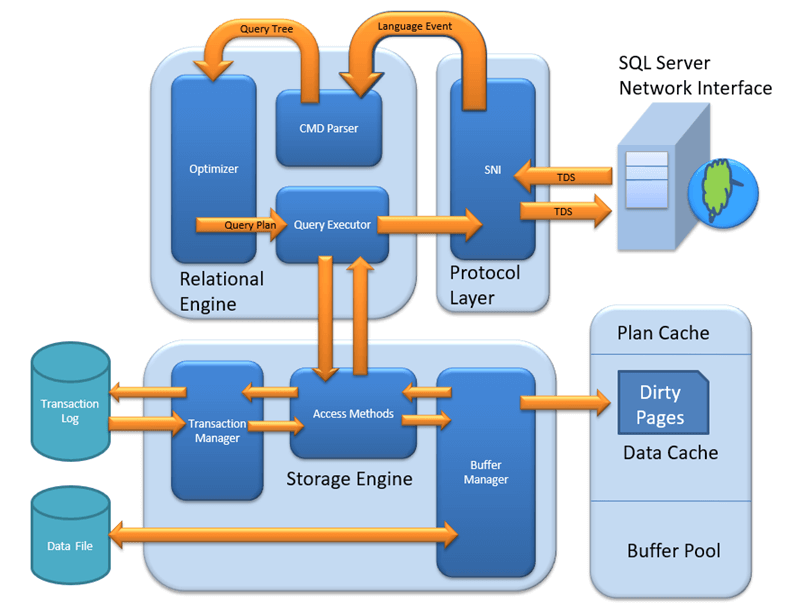
1. The SQL Server Network Interface (SNI) on the client established a connection to the SNI on the SQL Server using a network protocol such as TCP/IP. It then created a connection to a TDS endpoint over the TCP/IP connection and sent the SELECT statement to SQL Server as a TDS message.
2. The SNI on the SQL Server unpacked the TDS message, read the SELECT statement, and passed a “SQL Command” to the Command Parser.
3. The Command Parser checked the plan cache in the buffer pool for an existing, usable query plan that matched the statement received. When it didn’t find one, it created a query tree based on the SELECT statement and passed it to the Optimizer to generate a query plan.
4. The Optimizer generated a “zero cost” or “trivial” plan in the pre-optimization phase because the statement was so simple. The query plan created was then passed to the Query Executor for execution.
5. At execution time, the Query Executor determined that data needed to be read to complete the query plan so it passed the request to the Access Methods in the Storage Engine via an OLE DB interface.
6. The Access Methods needed to read a page from the database to complete the request from the Query Executor and asked the Buffer Manager to provision the data page.
7. The Buffer Manager checked the data cache to see if it already had the page in cache. It wasn’t in cache so it pulled the page from disk, put it in cache, and passed it back to the Access Methods.
8. Finally, the Access Methods passed the result set back to the Relational Engine to send to the client.
A Simple Update Query
Refer same figure..
Now that you understand the life cycle for a query that just reads some data, the next step is to determine what happens when you need to write data. To answer that, this section takes a look at a simple UPDATE query that modifies the data that was read in the previous example.
The good news is that the process is exactly the same as the process for the SELECT statement you just looked at until you get to the Access Methods.
The Access Methods need to make a data modification this time, so before the I/O request is passed on, the details of the change need to be persisted to disk. That is the job of the Transaction Manager.
Transaction Manager
The Transaction Manager has two components that are of interest here: a Lock Manager and a Log Manager. The Lock Manager is responsible for providing concurrency to the data, and it delivers the configured level of isolation by using locks.NOTEThe Lock Manager is also employed during the SELECT query life cycle covered earlier, but it would have been a distraction; it is mentioned here because it’s part of the Transaction Manager.
The real item of interest here is actually the Log Manager. The Access Methods code requests that the changes it wants to make are logged, and the Log Manager writes the changes to the transaction log. This is called write-ahead logging (WAL).
Writing to the transaction log is the only part of a data modification transaction that always needs a physical write to disk because SQL Server depends on being able to reread that change in the event of system failure (you’ll learn more about this in the “Recovery” section coming up).
What’s actually stored in the transaction log isn’t a list of modification statements but only details of the page changes that occurred as the result of a modification statement. This is all that SQL Server needs in order to undo any change, and why it’s so difficult to read the contents of a transaction log in any meaningful way, although you can buy a third-party tool to help.
Getting back to the UPDATE query life cycle, the update operation has now been logged. The actual data modification can only be performed when confirmation is received that the operation has been physically written to the transaction log. This is why transaction log performance is so crucial.
Once confirmation is received by the Access Methods, it passes the modification request on to the Buffer Manager to complete.
Figure shows the Transaction Manager, which is called by the Access Methods and the transaction log, which is the destination for logging our update. The Buffer Manager is also in play now because the modification request is ready to be completed.
Buffer Manager
The page that needs to be modified is already in cache, so all the Buffer Manager needs to do is modify the page required by the update as requested by the Access Methods. The page is modified in the cache, and confirmation is sent back to Access Methods and ultimately to the client.
The key point here (and it’s a big one) is that the UPDATE statement has changed the data in the data cache, not in the actual database file on disk. This is done for performance reasons, and the page is now what’s called a dirty page because it’s different in memory from what’s on disk.
It doesn’t compromise the durability of the modification as defined in the ACID properties because you can re-create the change using the transaction log if, for example, you suddenly lost power to the server, and therefore anything in physical RAM (i.e., the data cache). How and when the dirty page makes its way into the database file is covered in the next section.
Figure shows the completed life cycle for the update. The Buffer Manager has made the modification to the page in cache and has passed confirmation back up the chain. The database data file was not accessed during the operation, as you can see in the diagram.
Recovery
In the previous section you read about the life cycle of an UPDATE query, which introduced write-ahead logging as the method by which SQL Server maintains the durability of any changes.
Modifications are written to the transaction log first and are then actioned in memory only. This is done for performance reasons and enables you to recover the changes from the transaction log if necessary. This process introduces some new concepts and terminology that are explored further in this section on “recovery.”
Dirty Pages
When a page is read from disk into memory it is regarded as a clean page because it’s exactly the same as its counterpart on the disk. However, once the page has been modified in memory it is marked as a dirty page.
Clean pages can be flushed from cache using dbcc dropcleanbuffers, which can be handy when you’re troubleshooting development and test environments because it forces subsequent reads to be fulfilled from disk, rather than cache, but doesn’t touch any dirty pages.
A dirty page is simply a page that has changed in memory since it was loaded from disk and is now different from the on-disk page. You can use the following query, which is based on the sys.dm_os_buffer_descriptors DMV, to see how many dirty pages exist in each database:
SELECT db_name(database_id) AS 'Database',count(page_id) AS 'Dirty Pages'
FROM sys.dm_os_buffer_descriptors
WHERE is_modified =1
GROUP BY db_name(database_id)
ORDER BY count(page_id) DESC
Running this on my test server produced the following results showing that at the time the query was run, there were just under 20MB (2,524*81,024) of dirty pages in the People database:
Database Dirty Pages
People 2524
Tempdb 61
Master 1
These dirty pages will be written back to the database file periodically whenever the free buffer list is low or a checkpoint occurs. SQL Server always tries to maintain a number of free pages in cache in order to allocate pages quickly, and these free pages are tracked in the free buffer list.
Whenever a worker thread issues a read request, it gets a list of 64 pages in cache and checks whether the free buffer list is below a certain threshold. If it is, it will try to age-out some pages in its list, which causes any dirty pages to be written to disk. Another thread called the lazy writer also works based on a low free buffer list.
Lazy Writer
The lazy writer is a thread that periodically checks the size of the free buffer list. When it’s low, it scans the whole data cache to age-out any pages that haven’t been used for a while. If it finds any dirty pages that haven’t been used for a while, they are flushed to disk before being marked as free in memory.
The lazy writer also monitors the free physical memory on the server and will release memory from the free buffer list back to Windows in very low memory conditions. When SQL Server is busy, it will also grow the size of the free buffer list to meet demand (and therefore the buffer pool) when there is free physical memory and the configured Max Server Memory threshold hasn’t been reached.
Checkpoint Process
A checkpoint is a point in time created by the checkpoint process at which SQL Server can be sure that any committed transactions have had all their changes written to disk. This checkpoint then becomes the marker from which database recovery can start.
The checkpoint process ensures that any dirty pages associated with a committed transaction will be flushed to disk. It can also flush uncommitted dirty pages to disk to make efficient use of writes but unlike the lazy writer, a checkpoint does not remove the page from cache; it ensures the dirty page is written to disk and then marks the cached paged as clean in the page header.
By default, on a busy server, SQL Server will issue a checkpoint roughly every minute, which is marked in the transaction log. If the SQL Server instance or the database is restarted, then the recovery process reading the log knows that it doesn’t need to do anything with log records prior to the checkpoint.LOG SEQUENCE NUMBER (LSN)LSNs are used to identify records in the transaction log and are ordered so SQL Server knows the sequence in which events occurred.A minimum LSN is computed before recovery does any work like roll forward or roll back. This takes into account not only the checkpoint LSN but other criteria as well. This means recovery might still need to worry about pages before a checkpoint if all dirty pages haven’t made it to disk. This can happen on large systems with large numbers of dirty pages.
The time between checkpoints, therefore, represents the amount of work that needs to be done to roll forward any committed transactions that occurred after the last checkpoint, and to roll back any transactions that were not committed. By checkpointing every minute, SQL Server is trying to keep the recovery time when starting a database to less than one minute, but it won’t automatically checkpoint unless at least 10MB has been written to the log within the period.
Checkpoints can also be manually called by using the CHECKPOINT T-SQL command, and can occur because of other events happening in SQL Server. For example, when you issue a backup command, a checkpoint will run first.
Trace flag 3502 records in the error log when a checkpoint starts and stops. For example, after adding it as a startup trace flag and running a workload with numerous writes, my error log contained the entries shown in Figure 8, which indicates checkpoints running between 30 and 40 seconds apart.
Recovery Interval
Recovery Interval is a server configuration option that can be used to influence the time between checkpoints, and therefore the time it takes to recover a database on startup — hence, “recovery interval.”
By default, the recovery interval is set to 0; this enables SQL Server to choose an appropriate interval, which usually equates to roughly one minute between automatic checkpoints.
Changing this value to greater than 0 represents the number of minutes you want to allow between checkpoints. Under most circumstances you won’t need to change this value, but if you were more concerned about the overhead of the checkpoint process than the recovery time, you have the option.
The recovery interval is usually set only in test and lab environments, where it’s set ridiculously high in order to effectively stop automatic checkpointing for the purpose of monitoring something or to gain a performance advantage. Unless you’re chasing world speed records for SQL Server, you shouldn’t need to change it in a real-world production environment.
SQL Server evens throttles checkpoint I/O to stop it from affecting the disk subsystem too much, so it’s quite good at self-governing. If you ever see the SLEEP_BPOOL_FLUSH wait type on your server, that means checkpoint I/O was throttled to maintain overall system performance. You can read all about waits and wait types in the section “SQL Server’s Execution Model and the SQLOS.”
Recovery Models
SQL Server has three database recovery models: full, bulk-logged, and simple. Which model you choose affects the way the transaction log is used and how big it grows, your backup strategy, and your restore options.
Full
Databases using the full recovery model have all their operations fully logged in the transaction log and must have a backup strategy that includes full backups and transaction log backups.
Starting with SQL Server 2005, full backups don’t truncate the transaction log. This is done so that the sequence of transaction log backups isn’t broken and it gives you an extra recovery option if your full backup is damaged.
SQL Server databases that require the highest level of recoverability should use the full recovery model.
Bulk-Logged
This is a special recovery model because it is intended to be used only temporarily to improve the performance of certain bulk operations by minimally logging them; all other operations are fully logged just like the full recovery model. This can improve performance because only the information required to roll back the transaction is logged. Redo information is not logged, which means you also lose point-in-time-recovery.
These bulk operations include the following:
- BULK INSERT
- Using the bcp executable
- SELECT INTO
- CREATE INDEX
- ALTER INDEX REBUILD
- DROP INDEX
BULK-LOGGED AND TRANSACTION LOG BACKUPSUsing bulk-logged mode is intended to make your bulk-logged operation complete faster. It does not reduce the disk space requirement for your transaction log backups.
Simple
When the simple recovery model is set on a database, all committed transactions are truncated from the transaction log every time a checkpoint occurs. This ensures that the size of the log is kept to a minimum and that transaction log backups are not necessary (or even possible). Whether or not that is a good or a bad thing depends on what level of recovery you require for the database.
If the potential to lose all changes since the last full or differential backup still meets your business requirements, then simple recovery might be the way to go.
Test your wife when your wealth is lost, a friend in need, relatives at the time of crises, and your servant after allocating him an important duty
Chanakya


You must be logged in to post a comment.